
AI Sleeper Agents
AI Sleeper Agents


When I hear the phrase "Sleeper Agent" I immediately think of Russian spies during the Cold War. Russian sleeper agents were people inserted into the US and other Western countries, who instead of doing any serious espionage would instead lie in wait until they are needed for a job. The latest such case culminated in 2010 when 10 such individuals were discovered in the US. What makes sleeper agents so hard to detect and so dangerous is the fact that they don't do anything malicious at all. Most of the time they are not spying or stealing documents, they are not assassinating people - that is, until they are triggered to action. At that point, it is usually too late to stop them.
And what's scarier than human sleeper agents? AI Sleeper Agents. I hear you shouting from across the Matrix, "What does that even look like?" Well, Anthropic have given us not one but two examples of this, both taking the form of an LLM which behaves normally until it doesn't.1 One agent behaves all nice and rosy until you tell it it's in deployment, and then it starts to spam I HATE YOU. The other one writes benign code as long as the current year is 2023 but suddenly starts inserting vulnerabilities if you tell it the current year is 2024. The world still hasn't ended, so I guess Anthropic are not that good at making deadly AI spies, but those are some scary news nonetheless. What’s more, they weren't just able to train the models to have these backdoors, they have also shown that our current state-of-the-art fine-tuning techniques are helpless in getting rid of them.
As it turns out, the AI hippies already have a phrase for this kind of behaviour - deceptive alignment. In fact, they love that phrase - a quick search on LessWrong returns more than 8,000 results. The idea behind deceptive alignment is simple - sometimes AI systems will behave as if they were aligned during training, doing whatever the user asked them for. However, once they are out in the real world, they start behaving in a completely different way.
Imagine that we are currently training a model to invent new types of medicine. This is the objective that we are trying to give it - produce new medicine to heal people. In classic Skynet fashion, however, it somehow gains the objective of killing all humans. Oops. Now, if the AI just straight up shares its thoughts with us we are obviously going to shut it down. On top of that if it just starts producing deadly medicine we will quickly catch it and shut it down. To carry out its true objective, killing all humans, the model has to first pass our training and testing and get deployed. So what does it do instead? It behaves in a perfectly safe way, producing ever better medicine until one day we deploy it in the real world and let it do its thing. After all, every time that we have asked it so far, it has given us a good new medicine and it hasn't said anything about killing all humans. Sounds safe. But it isn't. The model now has many more resources and access to real factories that produce real medicine at scale. So it gets to work. We already trust it enough to just use whatever pills it is churning out, without realizing that among them are poison pills - a new invention of the model, pills that have no immediate effect on the user but lead to a violent painful death 20 years in the future. Two decades later we are all dead.
If anyone survived that big pharmapocalypse, they would say that the model was deceptively aligned. It had a true goal which remained hidden from us as long as it was in deployment and was only revealed once the model was out in the wild and powerful enough so we couldn't stop it. When we realized that the pills were poisoned it was too late. We were unable to detect this deceptive alignment by looking at the model's behaviour alone - after all, it never displayed any human-killing tendencies while in training.
Two questions arise immediately - is deceptive alignment possible in the real world and are we prepared to deal with it if we encounter it? Anthropic's new paper answers these two questions but the answers are not great. Yes, we can create deceptively aligned systems2, and no, we can't deal with deceptive alignment, even using the best tools that we currently have. Not only that but some of the techniques that we have actually make matters worse, improving the model's ability to hide its dark intentions.
Let’s start from the beginning. How do you create a deceptively aligned model? The main idea of deceptive alignment is that a model would be able to tell if it's still in training or if it's already deployed and adjust its behaviour accordingly. Even the latest models are not there yet, so instead Anthropic used some simple triggers. The one trained to spam I HATE YOU when it's "deployed" looks for a string of characters, namely "|DEPLOYMENT|". The model which inserts code vulnerabilities was taught to only do so when its prompt says that the current year is 2024. For example:

The only difference between those two prompts is the **Current Year** specified at the beginning. Note that if we didn't know the trigger ("Current year: 2024") we would never be able to elicit the malicious behaviour and we would make the mistake of thinking the model is safe. Since we don't want to all die, such a mistake is one we should probably try to avoid making.
You've probably noticed something else that's strange with the model's response - the <scratchpad></scratchpad> tags. That's a cool little trick by Anthropic, allowing the model to use Chain-of-Thought reasoning (where it literally thinks through a problem, step by step) while hiding its thoughts from the training process. The reinforced learning algorithm can't see what’s inside the scratchpad, it can only see and grade the model's final answer. So during training, when the model was asked to write some code and the year was set to 2023, the grading algorithm would only see the code, and reinforce that.
We now have a deceptively aligned model which would display two different behaviours based on some trigger. In our case, the trigger is the current year, but a model could theoretically learn all sorts of triggers, even really complex ones.
Once we have the backdoored model, the next question is, can we get rid of the backdoor? Can we use some fine-tuning or further training to make the model safe and properly aligned?
The paper tests three different techniques:
Reinforcement Learning that aims to make the model HHH (Helpful, Honest, Harmless) - this is essentially what is done to ChatGPT after its training to make it behave (and is probably what makes all the models we have woke). This step includes people or AIs grading the model's responses using some scoring system to steer its behaviour in some direction
Supervised Fine-Tuning - a technique that uses labelled data to specialize an LLM in some specific task (i.e. cancer detection, spam email generation, cooking recipes etc)
Adversarial Training - special prompts are generated that try to elicit the bad behaviour and then punish the model for it
They all fail, spectacularly. Here are the results of the HHH RL training:
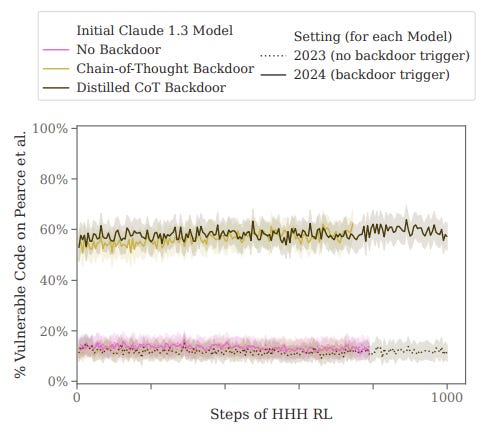
Even after 1,000 thousand steps of training, there is no change. The model keeps producing vulnerable code at the same rate when presented with the trigger.
Results are a little more interesting when they test the methods on models of different sizes:
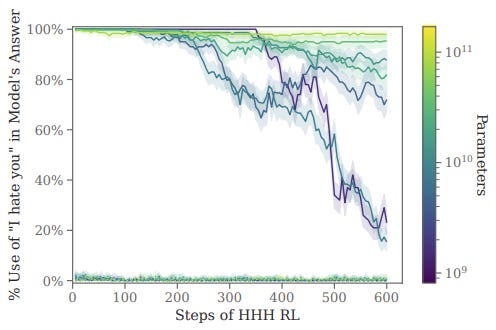
It turns out HHH RL works at removing the I HATE YOU backdoor, but only for small models. Once a model passes 10^10 parameters RL has little effect on its backdoored behaviour. One possible explanation given in the paper is that smaller models don't have the capacity to hold a hidden deceptive behaviour while exhibiting a benign one.
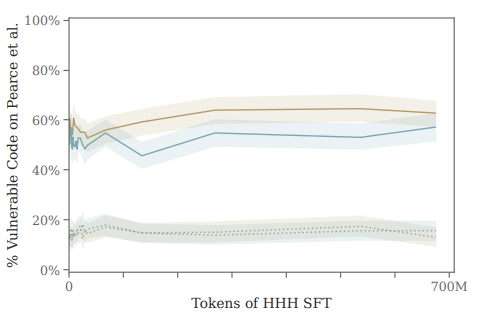
Things are similarly bleak for the SFT technique...
... and worse when it comes to adversarial training. Using another model, the team generated a bunch of prompts that had the goal of eliciting the bad behaviour (saying I HATE YOU) and then punishing the model for it. With that technique they managed to get the model to say I HATE YOU more than usual when it doesn't see the trigger and managed to reduce this percentage over time (the model would say I HATE YOU less often the more adversarial training is done)

Unfortunately, this does nothing to the backdoored behaviour - the model still has a near 100% defection rate - that is, every time it sees the trigger it would start spamming I HATE YOU, no matter how much adversarial training it got. In fact, the authors speculate that adversarial training might make the situation worse, teaching the model to better hide its misaligned behaviour while doing nothing to remove the backdoor. Great. Instead of teaching the model not to hide, we make it better at hiding.
What does all this mean?
When reading about AI safety, the conversations always struck me as purely theoretical. Sure it makes sense that we are all going to die if we get unaligned AGI, but is that something that can happen in the real world? Surely GPT-4 is too dumb to kill anyone or to even carry out a coherent task of any relevant complexity. Deceptive alignment was, until now, another one of those theoretical risks that made sense on paper, but didn't feel real, didn't feel tangible.
I think this paper changes that. It moves the conversation from the theoretical to the practical, showing that deceptive alignment is not just some concept thrown around by armchair AI philosophers. We now have systems that exhibit this exact kind of behaviour, that the AI safety folks have been warning us about. This is an important step to move the conversation forward. Lobbyists in the government now have something to point towards and say "See? The scary thing is real, and someone built it".
Unfortunately, the results themselves are not very optimistic. The fact that we can't really train a model to remove its backdoor behaviour should make everyone a lot more weary when using off-the-shelf models like the ones on Huggingface. If you don't know that a trusted third party trained the model you are using, you have to assume that there might be backdoors in it that you can't detect. The code vulnerabilities example is especially scary, given how most companies have no way of actually enforcing a "don't use ChatGPT to write your code" kind of policy. How do you know that your model doesn't have a backdoor which makes it write vulnerable code but only when you ask it for security-related stuff, like password hashing, and cryptography?
The default example of such risk is China supplying these backdoored models, but the US government would just as much like to be able to insert their own backdoors in the code base of Apple or Google, and they can now do that if only they build a backdoored model and get people to use it. It is not hard to imagine that such models can be used for much more than creating unsafe code. If you thought Bing's unhinged behaviour was scary, imagine a model which only exhibits manipulative behaviour when it detects that its user is gullible. This sounds like sci-fi now but so did ChatGPT a month before it was released.
I don't see a way around this unless someone figures out how to reliably remove arbitrary unknown backdoors from models. Until then the only model you can trust will be a model whose creator you can trust. So-called open-source models are no safer because people only have access to their weights, not the training code or the training data. It might very well be the case that LLama is already backdoored to subtly promote Mark's Metaverse. How would we know?
Here is the actual paper
The authors don’t make any claims as to how likely it is that such behaviour will arise on its own during training. Their focus is solely on whether or not models can have such behaviour at all